[ad_1] YouTube is rolling out an update with changes across desktop, mobile, TV, and YouTube Music. Key Changes & New Features User Interface The update brings visual changes to YouTube’s interface across all platforms. These …
Continue reading
Unlocking the Secrets of SEO
[ad_1] YouTube is rolling out an update with changes across desktop, mobile, TV, and YouTube Music. Key Changes & New Features User Interface The update brings visual changes to YouTube’s interface across all platforms. These …
Continue reading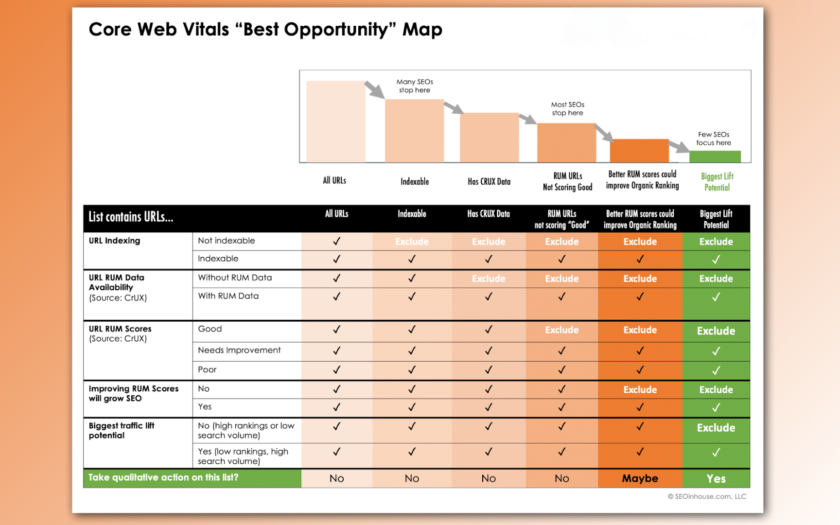
[ad_1] A big challenge for many SEO professionals is identifying what needs to change to move the needle. This article recaps a topic from my SMX Advanced presentation on determining which URLs you should prioritize …
Continue reading
[ad_1] Google rolled out a new Core Web Vitals tool called CrUX Vis that shows you hidden patterns in performance scores and offers guidance on what to improve. The data is sourced from the CrUX …
Continue reading
[ad_1] Google’s Lighthouse doesn’t use the Interaction to Next Paint (INP) metric in its standard tests, despite INP being one of the Core Web Vitals. Barry Pollard, Web Performance Developer Advocate on Google Chrome, explained …
Continue reading
[ad_1] Google’s John Mueller answered a question about why Google indexes pages that are disallowed from crawling by robots.txt and why the it’s safe to ignore the related Search Console reports about those crawls. Bot …
Continue reading
[ad_1] Google’s Martin Splitt answered a question in the SEO Office Hours podcast about whether reproducing YouTube video content into text on a web page would be seen as duplicate content and have a negative …
Continue reading
[ad_1] Google has defined a set of metrics site owners should focus on when optimizing for page experience. Core Web Vitals metrics are part of Google’s page experience factors that all websites should strive to …
Continue reading